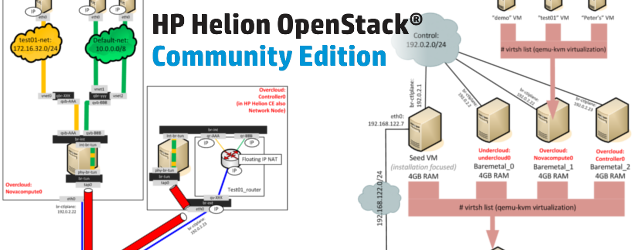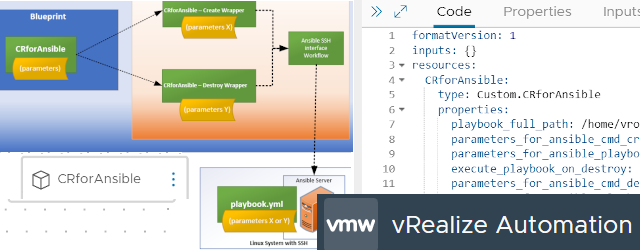



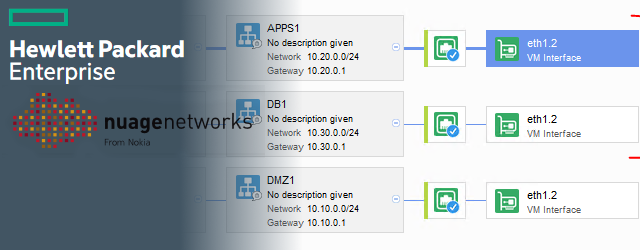
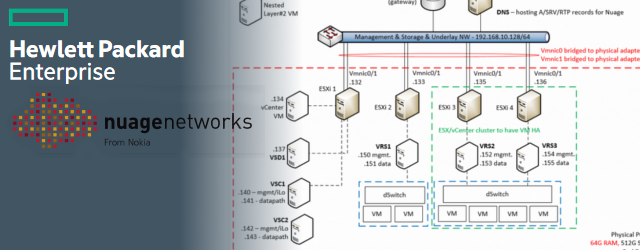

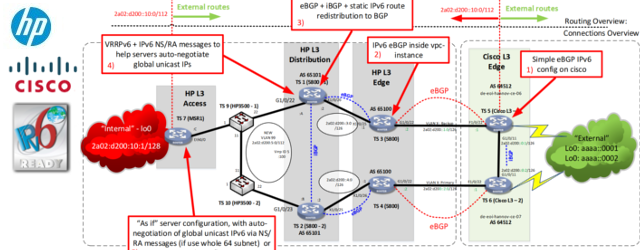


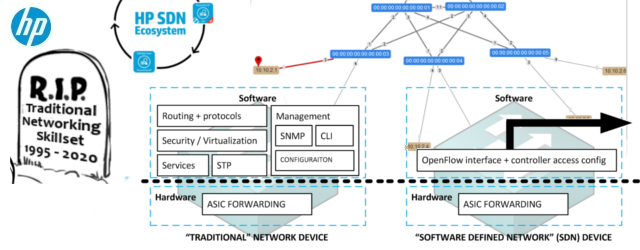


vmWare vRealize Automation (with embedded vRO) – Full Example of Custom Resources for Executing Ansible Playbooks from Blueprints
This articles exists because I spend a lot of time in the last year inside vmware vRealize Automation (vRA) that includes an embedded vRealize Orchestrator (vRO) on a undisclosed project. … Read More